万达平台智慧金融系列講座第四十三期
本次講座由謝富生老師帶來《機器學習和因果推斷》。機器學習是人工智能、計算機科學等領域的重要研究方向之一,近年來深受人們的關註和喜愛,尤其是自2006年美國卡內基梅隆大學(CMU)專門設立機器學習系以來🗾🤜🏼,更是在全球產生了史無前例的推動作用。人們意識到在現代科學研究方法中,如果還停留在計算的技術層面上🕯©️,那整個科學的研究進程可能會受到限製。如對物質特性的分析、分子結構的物理性質的分析等,這些僅憑計算是非常難以實現的🙍🏿♀️。這些數據結構的深層關系和語義的不確定性使得僅憑計算技術來完成這些任務就顯得遠遠不夠了👩🏽✈️。從機器學習的進展來看,已經發展到了李群🧑✈️、動態模糊集合👨👩👧、動態模糊邏輯等相關領域🌱。
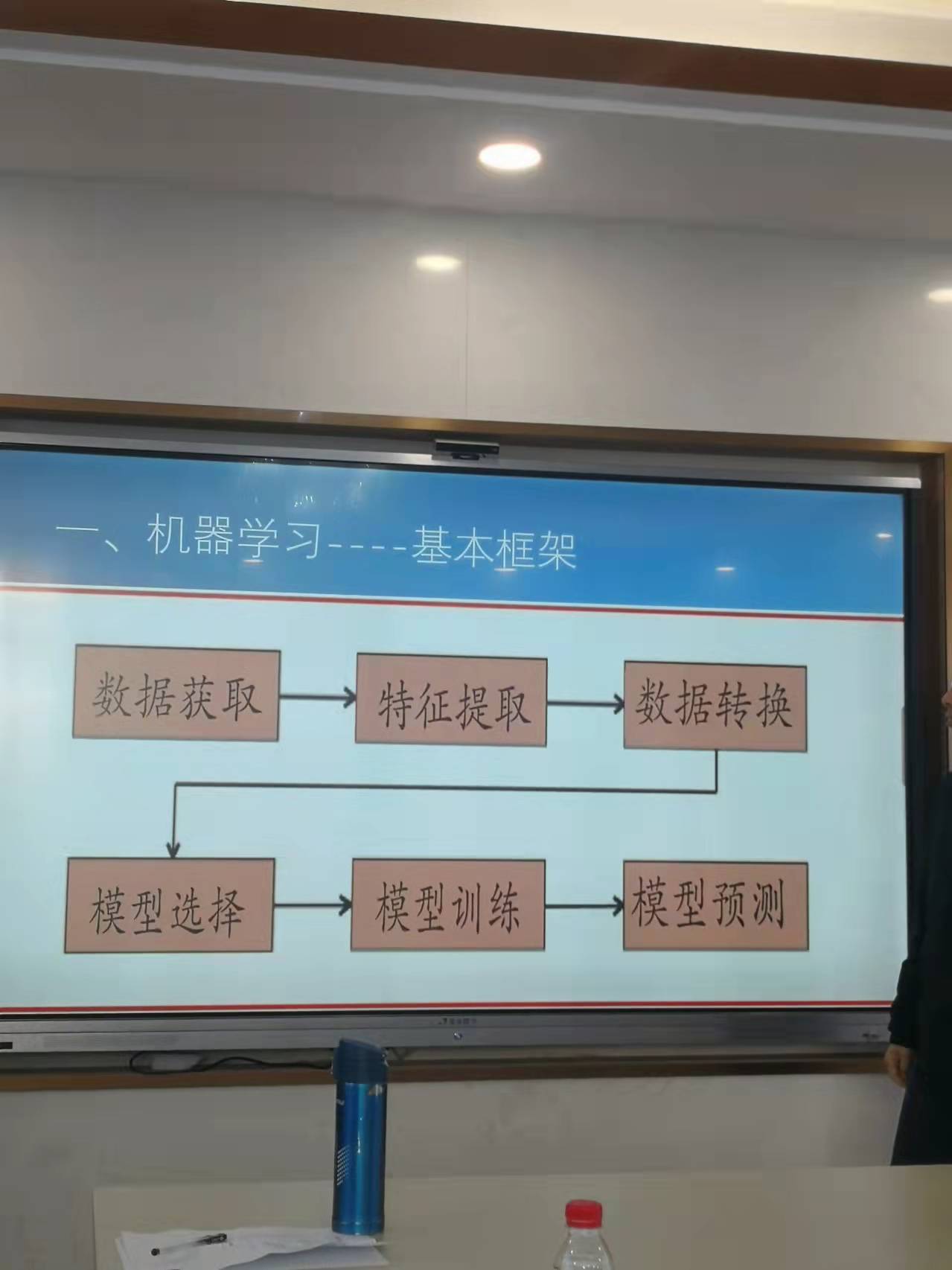
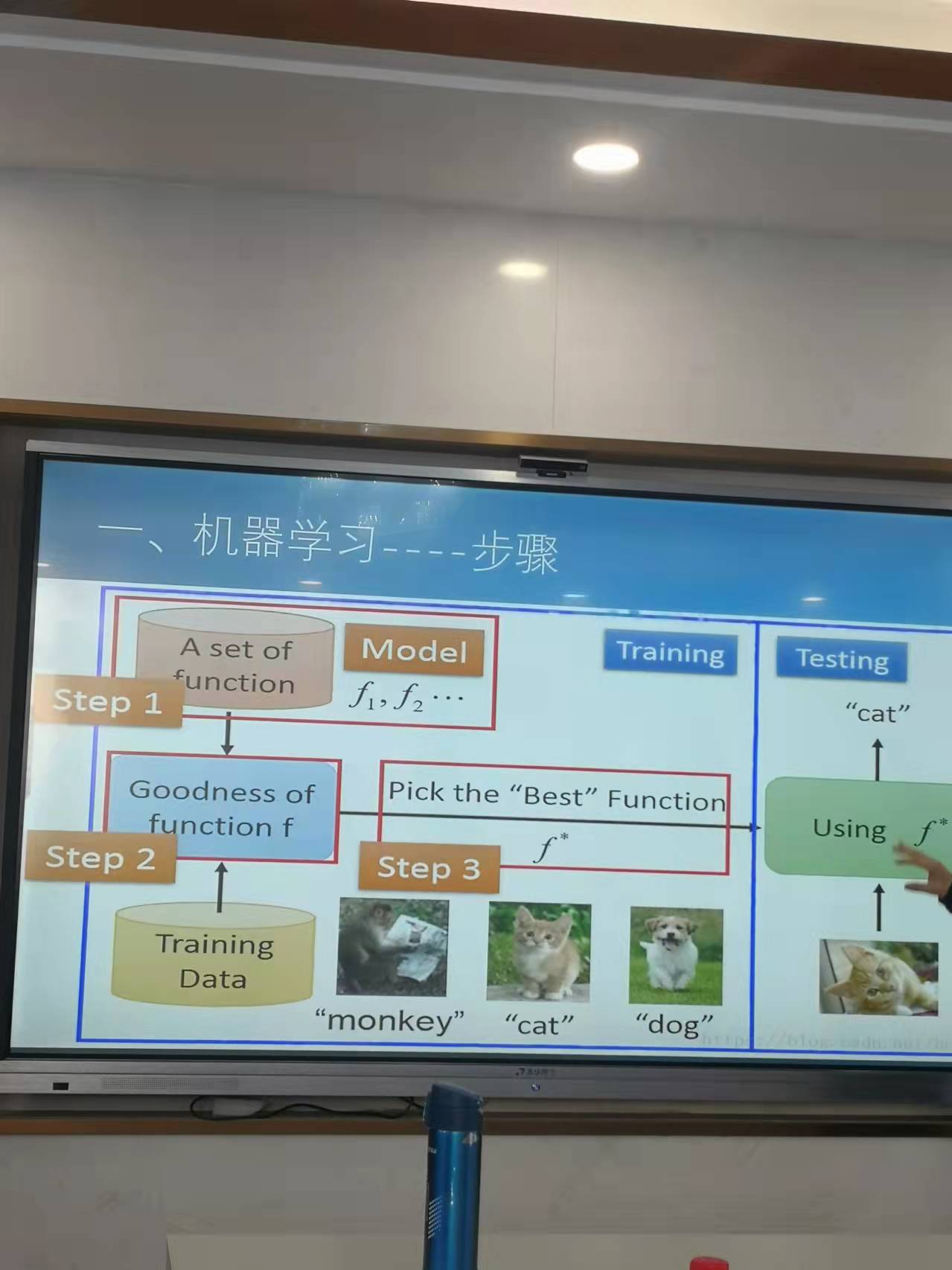
謝富生老師帶來的機器學習和因果推斷主要分成四個部分🍩,分別是機器學習概述、機器學習模型不穩定原因、RCM模型以及因果推斷案例🎨。謝老師將機器學習歸結為一種實現人工智能的方法。本質是以數理模型為核心工具、結合控製論、認知心理學等其他學科的研究成果🍭,最終由計算機系統模擬人類的感知、推理、學習、決策等功能。從機器學習的架構來看🫱🏽👼🏿,機器學習分為數據獲取、特征提取⛔、數據轉換🧒🏼🕵🏼♂️、模型選擇🤚🏽、模型訓練和模型預測。從訓練的角度來看🫒,首先使用訓練數據對函數進行訓練,在訓練的過程生成最優的函數🧝,然後選擇測試數據對函數進行測試,最終獲得結果👘。從機器學習的方法來看,可以將機器學習分為監督學習和無監督學習,在監督學習下分為回歸、分類和降維®️,無監督學習分為聚類和降維。如果進行細化可以分為線性回歸🤷🏼♀️、嶺回歸🙆🏿♂️、Lasso回歸🈂️、支持向量機、決策樹🍗、隨機森林⛺️、梯度樹提升、神經網絡🤚🏼、邏輯回歸🚋、線性判別分析、二次判別分析、K聚類算法、主成分分析等相關方法🌠。從風險角度來看😹🧗🏿♂️,機器學習是一種“連接主義”方法,且不具備邏輯推理能力🙇🏻♀️🧜🏼♀️,機器學習的結果是歷史經驗的總結🧘🏼♂️,存在失效的可能性。接下來,謝老師列舉了兩個例子,分別是選擇性偏差和混淆變量問題🦻🏻,他進一步指出,選擇性偏差是由於訓練問題所導致的👘🧑🏻💻,而混淆變量的產生則是源自多元回歸中可能存在的虛假關系🧏🏽♀️。談到機器學習中的不穩定原因,謝老師接著說到📈,機器學習中的不穩定源自數據問題和模型設置🤙🏽。從最終的評價標準來看,傾向性評分法的因果推斷流程為計算傾向評分並估計因果效應、評估各傾向性評分方法的均衡性以及最終的反駁。謝老師於是就Logistic回歸做了相應的說明。從最終反駁的角度來看,可以使用安慰劑數據法🧜🏿♀️、添加隨機混淆變量法以及子集數據法來對相關的回歸進行穩健性檢驗。一個應用的例子是Lalonde數據集🍄🟫,這個數據集包含了年齡🤿🦻🏼、教育年限、是否為黑人和西班牙人🧑🏻🌾、是否已婚、實際收入等等,使用三種傾向性評分法對該問題進行傾向性分析📧,最終可以得到傾向性得分和評價標準。再在這種方法上使用基金重倉、質押等問題作為主自變量㊗️,以股價的漲跌作為因變量進行調整👩🦼➡️🪂,再使用三種維度進行調整評價🎒,最終可以得到相關的結論。














(供稿 曹煥)



